In part 1 of this series, we answered the question of WHY open source components are often an attractive option when building a data lake of any significant size. In this second installment, we describe HOW to cost-effectively build a data lake out of open source components. We will share common architectural patterns as well as critical implementation details for the key components.
Designing an Open Source Data Lake
Data Flow Design
A typical data lake’s logical flow is comprised of these functional blocks:
- Data Sources
- Data Ingestion
- Storage Tier
- Data Processing & Enrichment
- Data Analysis Exploration
In this context, the data sources are generally streams or collections of raw, event-driven data (e.g. logs, clicks, IoT telemetry, transactions). A key characteristic of these data sources is that the data is far from clean - often due to constraints of time or compute power during collection. Noise in this data usually consists of duplicate or incomplete records with redundant or erroneous fields.
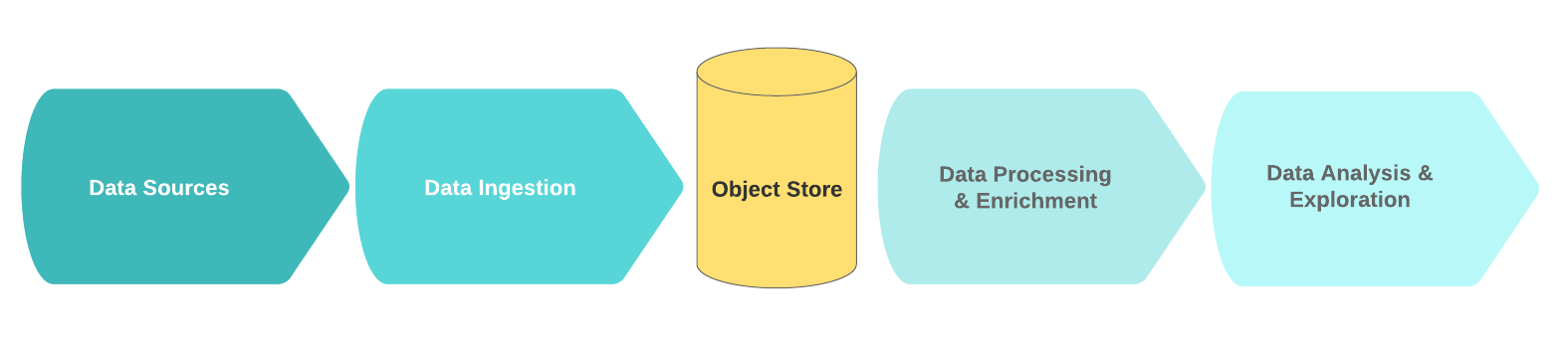
Given one or more data sources, we consume the raw data via an ingestion phase. The ingestion mechanism is most often implemented as one or more distributed message queues with a lightweight computational component responsible for initial data sanitization and persistence. In order to build an efficient, scalable, and coherent data lake, we strongly recommend a clear distinction between simple data sanitization and more complex enrichment tasks. One rule of thumb is that sanitization tasks should only require data from a single source and within a reasonable sliding window.
For example, a deduplication task that is bounded to only consider keys from events that are received within 60 seconds of each other from the same data source would be a typical sanitization task. On the other hand, a task that aggregates data from multiple data sources and/or across a relatively long time span (e.g. the last 24 hours) would probably be better suited for the batch analytics enrichment phase (which we will talk about below).
Once data has been ingested and sanitized, it is persisted into an object store/distributed file system to ensure resilience from any subsequent component failure. The data is normally written in a columnar format such as Parquet or ORC and is usually compressed via fast protocol such as Snappy for maximum storage efficiency and query performance.
When new data is written into the storage tier, a data catalog (which hosts the schema and the underlying metadata) can be dynamically updated using a serverless function crawler. The execution of such data crawler is normally event driven (arrival of new file into a specific location on an object store). Data stores are normally integrated with the data catalog in order to infer the underlying schema to make the data queryable.
The data usually lands in a dedicated location (or a “zone”) dedicated to the golden data. The data is called golden for a reason: it is still raw, semi-structured or unprocessed and it is your business logic’s primary “source of truth”. From here on the data is ready to be further enriched by the subsequent data pipelines.
During the enrichment process, the data is further modified and distilled according to the business logic. It is eventually stored in a structured format in one of the data stores (e.g. a document store, an RDBMS or an object store) that may be dedicated to on-line serving, BI analytics, data warehousing or model training.
Lastly, the analysis and data exploration is where the data consumption occurs. This is where the distilled data is transformed into business insights through visualizations, BI dashboards, reports and views. It is also a source of ML predictions, the outcome of which helps drive better business decisions.
Platform Components
A hybrid cloud data lake architecture requires a reliable and unified core abstraction layer that will allow us to deploy, coordinate, and run our workloads without being constrained by vendor API’s and resource primitives. Kubernetes is a great tool for this job since it allows us to efficiently deploy, orchestrate and run various data lake services and workloads in a reliable and cost efficient manner while exposing a unified API whether it is running on-premise or on any public or private cloud. We will dive deeper into the specifics of Kubernetes implementation details in a future post.
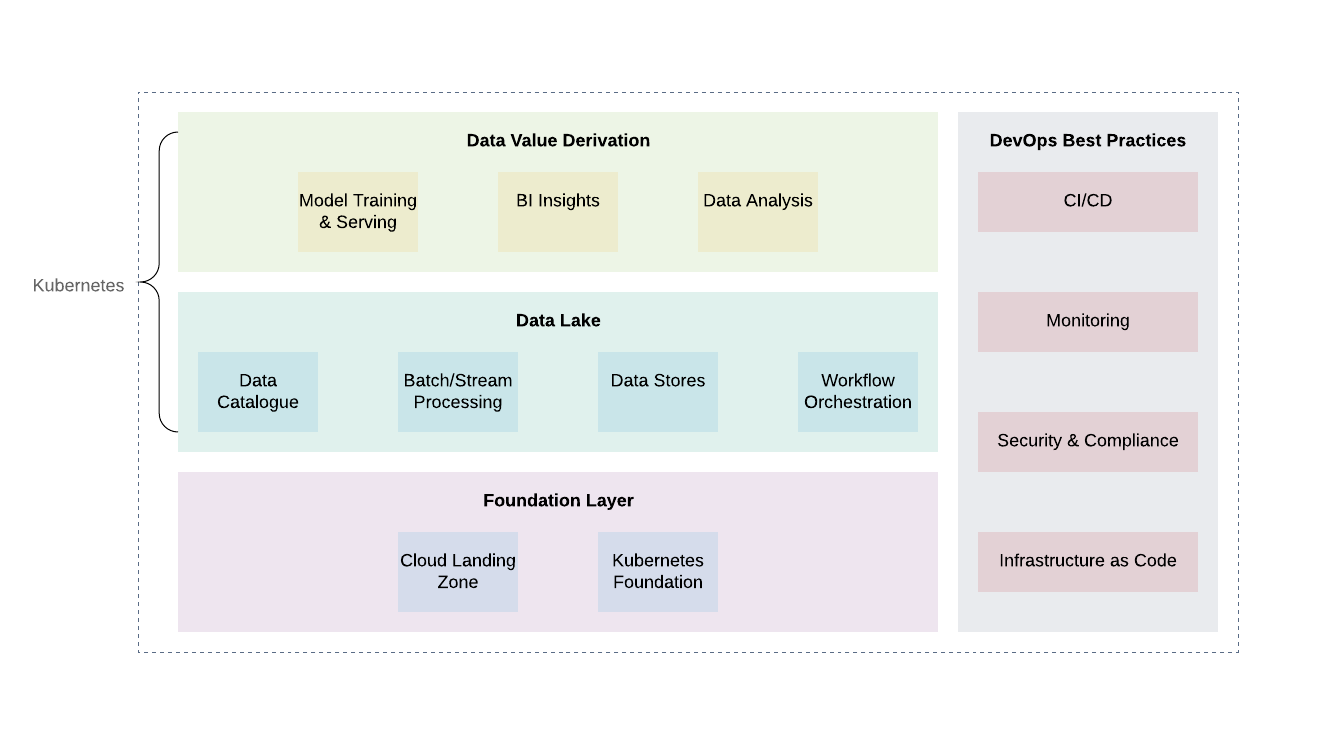
From a platform perspective, the foundation layer is where we deploy Kubernetes or equivalent thereof. The same foundation can be used to handle workloads beyond the data lake. A future-proof foundation layer incorporates cloud vendor best practices (functional and organizational account segregation, logging and auditing, minimal access design, vulnerability scanning and reporting, network architecture, IAM architecture etc) in order to achieve the necessary levels of security and compliance.
Above the foundation layer, there are two additional layers - the data lake and the data value derivation layers.
These two layers are mainly responsible for the core business logic as well as data platform pipelines. While there are many ways to host these two layers, Kubernetes is once again a good option because of its flexibility to support different workloads both stateless and stateful.
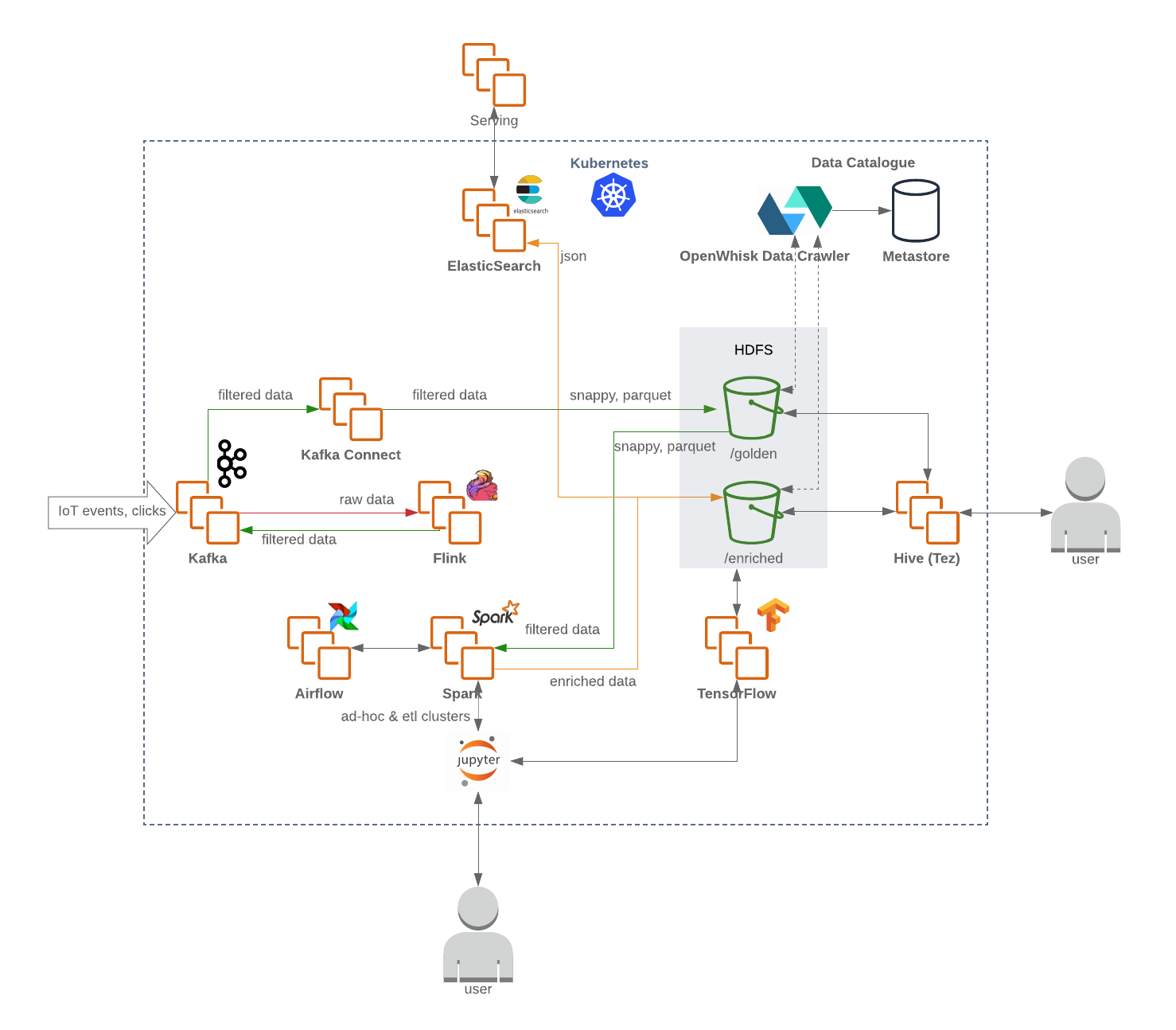
The data lake layer, typically includes all the necessary services that are responsible for ingestion (Kafka, Kafka Connect), filtering, enrichment and processing (Flink and Spark), workflow management (Airflow) as well as data stores such as distributed file-systems (HDFS) as well as RDBMS and NoSQL databases.
The uppermost layer, data value derivation, is essentially the “consumer” layer and includes components such as visualisation tools for BI insights, ad-hoc data exploration via data-science notebooks (Jupyter). Another important process that takes place on this layer is ML model training leveraging data sets residing on the data-lake.
It is important to mention that an integral part of every production grade data lake is the full adoption of common DevOps best practices such as infrastructure as code, observability, audit and security. These play a critical role in the solution and should be applied on every single layer in order to enable the necessary level of compliance, security and operational excellence.
--
Now, let’s deep dive further into the data lake architecture and review some of the core technologies involved in the process of ingestion, filtering, processing and storing our data. A good guiding principle for choosing open source solutions for any of the data lake stages is to look for a track record of wide industry adoption, comprehensive documentation and, of course, extensive community support.
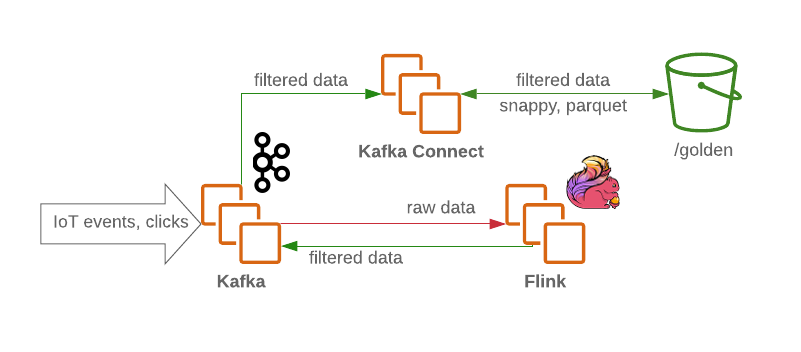
A Kafka cluster will receive the raw and unfiltered messages and will function as the data lake ingestion tier with its reliable message persistence and ability to support very high message throughput in a robust way. The cluster typically contains several topics for raw, processed (for stream processing) and dead letter (for malformed messages). For maximum security the brokers endpoints can terminate SSL, while encryption is turned on in the persistence volumes.
From that point, a Flink job consumes the messages from Kafka’s raw data topic and performs the required filtering and, when needed, initial enrichment. The data is then produced back to Kafka (into a separate topic dedicated to filtered/enriched data). In the event of failure, or when business logic changes, these messages can be replayed from the beginning of the log since they are persisted in Kafka. This is very common in streaming pipelines.
Meanwhile, any malformed, illegal messages are written by Flink into the dead letter topic for further analysis.
Using a Kafka Connect fleet backed by storage connectors, we are then able to persist the data into the relevant data store backends such as a golden zone on HDFS. In the event of a traffic spike, the Kafka Connect deployment can easily scale out to support a higher degree of parallelism resulting in higher ingestion throughput:
While writing into HDFS from Kafka Connect, it is usually a good idea to perform a content (topic) and date-based partitioning for query efficiency (less data to scan meaning less IO), for example:
hdfs://datalake-vol/golden/topic_name/2019/09/01/01/datafoo.snappy.parquet
hdfs://datalake-vol/golden/topic_name/2019/09/01/02/databar.snappy.parquet
Once the data was written to HDFS, a periodically scheduled serverless function (such as OpenWhisk or Knative) updates the metastore (which contains the metadata and schema settings) with the updated structure of the schema, so that it can be queried via SQL-like interfaces, such as Hive or Presto:
For the subsequent data flows and ETL coordination we can leverage Apache Airflow, which allows users to launch multi-step data pipelines using a simple Python object Directed Acyclic Graph (DAG). A user can define dependencies, programmatically construct complex workflows, and monitor scheduled jobs in an expressive UI.
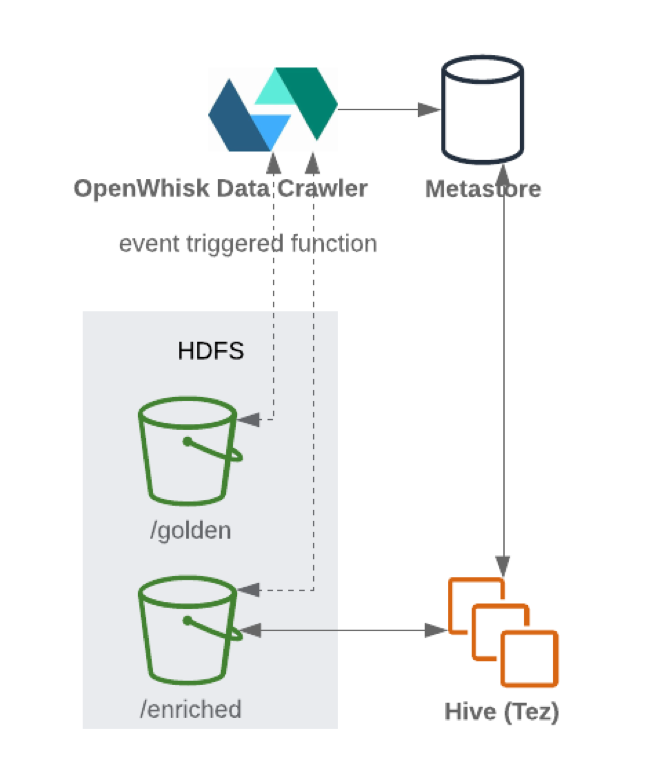
Airflow can also potentially handle the data pipeline for all things external to the cloud provider (e.g. pulling in records from an external API and storing in the persistence tier).
Being orchestrated by Airflow via dedicated operator plugin, Spark can then periodically further enrich the raw filtered data according to the business logic and prepare the data for consumption and exploration by your data scientists, business analysts and BI teams.
The data science team will be able to leverage JupyterHub to serve the Jupyter Notebooks, therefore enable effective multi-user, collaborative notebook interfaces with your data leveraging the Spark execution engine to perform aggregations and analysis.
The team can also leverage frameworks such as Kubeflow as a production-grade ML model training leveraging the scalability of Kubernetes. The resultant machine learning models can later be fed back into the serving layer.
Gluing all the pieces of the puzzle, the final architecture will look something like this:
Operational excellence
We’ve already mentioned that DevOps and DevSecOps principles are core components of every data lake and should never be overlooked. With great power comes great responsibility, especially when your business has structured and unstructured data now residing in one place.
One of the recommended approaches is to allow access only to specific services (via appropriate IAM service roles) and block any direct user access so that data cannot be manually altered by your team members. Also, a full audit with relevant trail services is essential for monitoring and safeguarding the data.
Data encryption is another important mechanism to protect your data. Data encryption at rest can be done by using KMS services to encrypt your persistent volumes for stateful sets and object store, while data encryption in transit can be achieved by using certificates on all UI’s as well as services such as Kafka, ElasticSearch endpoints.
We recommend a serverless scanner for resources that aren’t complaint with your policies, such that it is easy to discover issues as such untagged resources, non restrictive security groups.
We discourage any manual, ad-hoc deployments for any component of the data lake; every change should originate in a version control and go through a series of CI tests (regression, smoke tests etc) before getting deployed into the production data lake environment.
Cloud Native Data Lake - Epilogue
In this series of blog posts we’ve demonstrated the rationale and the architectural design of an open source data lake. As in most cases in IT, the choice of whether to adopt or not to adopt such an approach is not always obvious and can be dictated by a wide array of business and compliance requirements, budget and time constraints.
It is important to understand that the real cost benefit is usually observed when the solution is deployed at scale, since there is an initial investment in a platform that is made to support this flexible model of operation (as we have demonstrated in part 1).
Going with a cloud native data lake platform (whether it is hybrid or fully cloud native solution) is clearly a growing trend in the industry given the sheer amount of benefits this model offers. It has a high level of flexibility and protects against increasing lock-in. In the next installment we are going to drill down into a Kubernetes abstraction that enables hybrid data lake implementation.
Written by: Paul Podolny




