Data lakes have become the de-facto standard for Enterprises and Corporations looking to harness value and take advantage of their existing data. Ultimately, businesses do not care whether they’re running their workloads on public, private or hybrid cloud. They just want to make sure that they do not miss out on the opportunities their data offers.
Through our experience we’re convinced that when it comes to deploying data lakes, the public cloud is by far the cheapest option for deploying most of the data lake solutions.
The public cloud offers:
- Independently scaling of storage and compute capacity (don’t run servers when they’re not needed)
- Rapid innovation cycles providing virtually infinite scale spin up and spin down capabilities to test theories as fast as they are thought of
- Simple storage for both relational and non relational data
- Pay as you go flexibility
- Spot or preemptive compute capacity offering significant savings for batch analytics spikes
In this series of blogs, we will share some of OpsGuru’s experience building Open Source data lakes on public and hybrid clouds. We will also provide some detailed architecture examples of the most critical components for any data lake.
Why should I care about an Open Source Data Lake?
Two common questions we hear from our customers: “What value do Open Source solutions provide?” and “Why should I investigate building my own solution when my cloud provider can build one for me?”
First, let’s analyse in detail what it is that you’re really deciding when choosing cloud vendor solutions versus your own:
1) The True Total Cost of Ownership:
We will conduct a basic cost analysis of an ingestion pipeline running on AWS. We assume that we are evaluating Apache Kafka as an alternative to Kinesis Streams.
Kinesis Streams
Assuming we have a single stream that is used primarily for data ingestion:
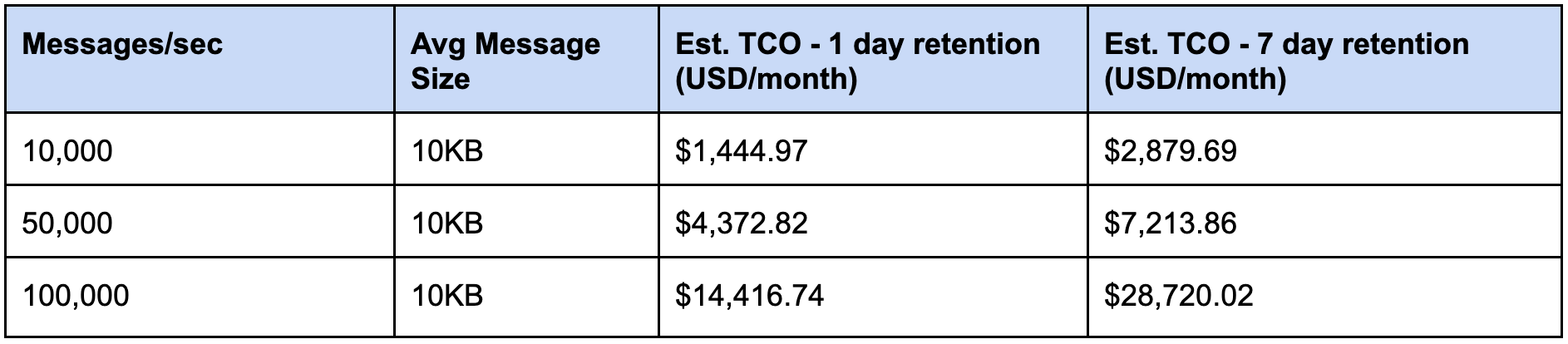
In order to ingest 50,000 messages per second with 24h of data retention, an annual cost of $52,400 is expected. This number doubles to $104,800 if your Kinesis stream is storing data with increased retention (up to a week).
*Open Source:*
Now, let’s look at an alternative, Kafka and Zookeeper running on top of Amazon EC2 or Kubernetes utilizing Stateful Sets.
A few assumptions are made here of course, compression (such as: ‘gzip’) is being used and we are replicating data (replication factor of 3) for increased redundancy:
- 3 x m3.medium machines with 10GB io1 EBS volumes for Zookeeper
- 3 x m5.2xlarge machines with 5TB st1 EBS volumes for Kafka
The cost of the infrastructure that is confidently able to handle similar workloads on demand, will be $1,840 per month which runs an annual cost of $22,080 per year. This excludes any other potential instance savings. Even if you factor-in some engineering effort the annual cost of your Open Source solution will be considerably cheaper than a vendor based solution. This is especially evident when you extrapolate out over longer terms:
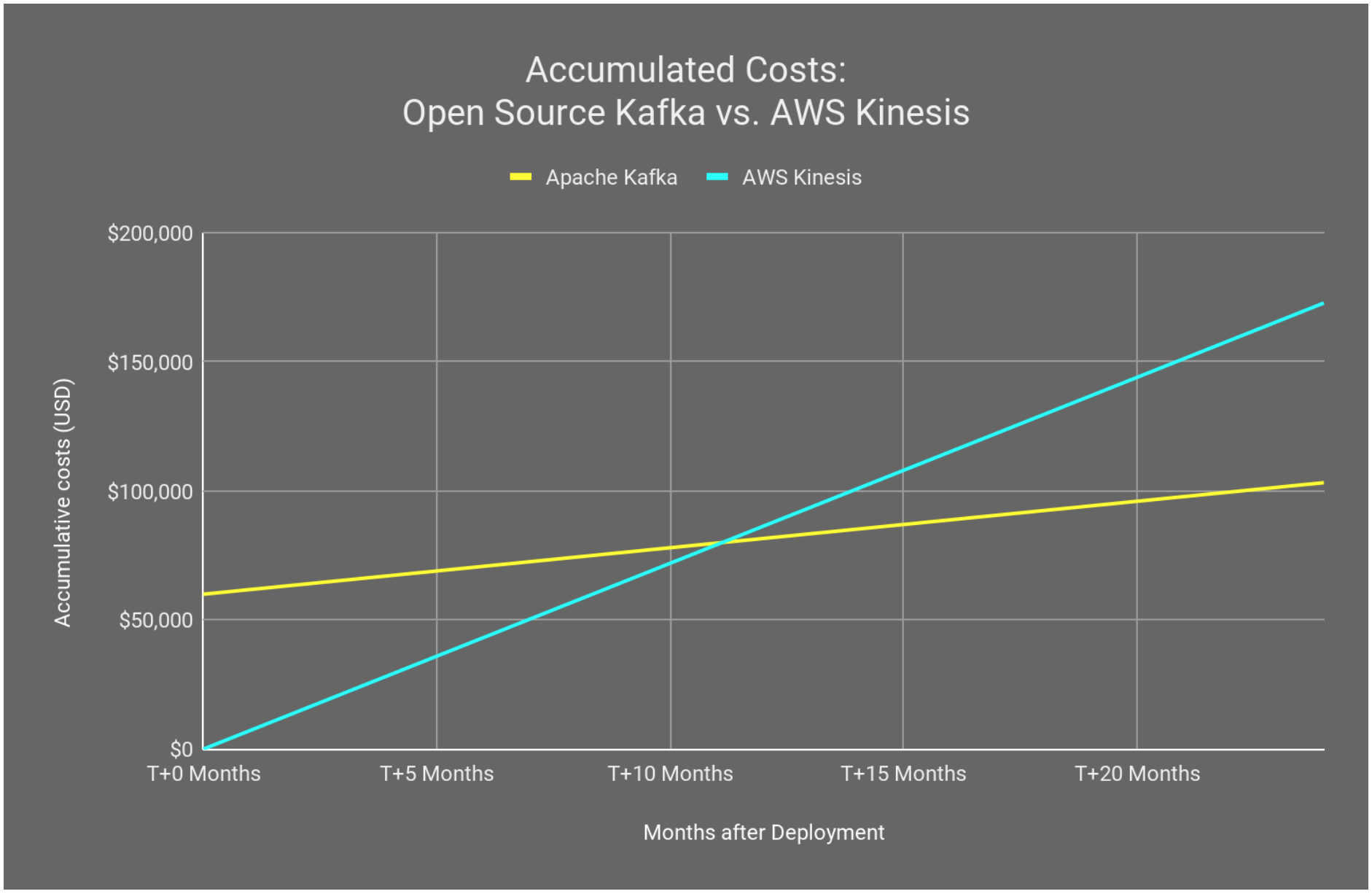
As shown above, we have factored in an initial expenses of approximately $60,000 for deploying an Open Source solution either through your own staff or by using a consultant, like OpsGuru. In this example, the break-even point happens within the first year of operation. Overall Kinesis is not cheaper than the Open Source example, and offers you less flexibility while locking your services into a specific cloud vendor. If you factor data growth of your streaming solution - the break-even point arrives even sooner.
Managed Kafka:
AWS recently released a managed Kafka solution, Amazon MSK, with similar configurations of instances as per our previous examples. This can be a much more appealing option, however it’s important to also conduct a cost benefit example for Amazon MSK. Depending on your configuration, our modelling shows that the calculated costs of Amazon MSK can be almost twice as expensive as the Open Source alternative.
An Amazon MSK deployment with almost identical configurations (3x kafka.m5.2xlarge brokers with similar storage) can cost $3,350 a month or $40,200 a year. While this is already almost double the cost of the Open Source alternative, it’s also important to note some rather large feature gaps when utilizing the service. Amazon MSK requires that you deploy your Kafka cluster across a minimum of 3 availability zones. While this is great for redundancy, there is a rather large hidden transfer cost when you factor in your application consuming data from brokers across availability zones. When you factor the $0.01/GB charge for data transfers you will find a pipeline processing 50,000 messages per second (of an average size of 10KB) will transfer ~500GB of data each day across availability zones. This adds an additional ~$4,562 per month and gives us a more accurate cost estimate of $90,000 to $100,000 per year.
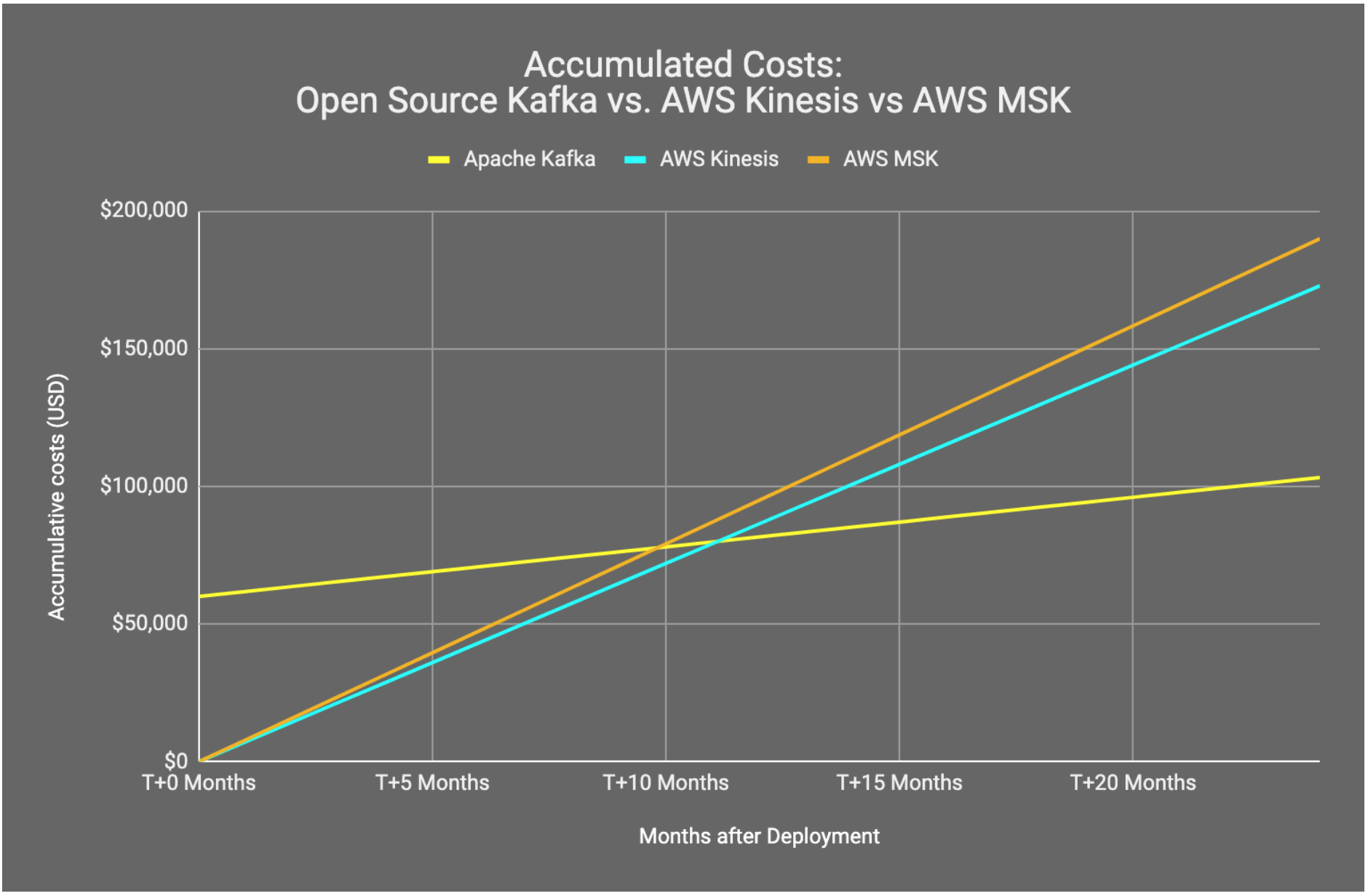
As your streaming throughput and retention requirements increase, vendor solutions quickly become less appealing. This can be well summarised as a rent vs buy argument, just like if you were looking for a place to live. We have seen time and time again, that an Open Source solution becomes cheaper and more appealing as volumes grow and time goes by.
* Reference: AWS cost calculator.

2 ) Vendor lock-in
Another key discussion point for an approach to deploying a data lake is vendor lock-in.
The main question we believe you need to ask yourself is: Given our business requirements to remain flexible across multiple cloud providers. Will our teams be able to migrate our services from vendor A to vendor B, without a significant engineering effort, at relatively low cost, and in a timely manner?
Obviously, there are some services that are so tightly integrated into the vendor’s platform that it is almost never worth trying to implement an Open Source alternative. Object stores like Amazon S3 and Google Cloud Storage are great examples. These global scale systems are very simple in an operational sense and in some cases even compatible with each others APIs. Because of this, we recommend utilizing a hybrid approach where some base primitives are consumed from a cloud vendor (Kubernetes, Blob Storage, etc.) but you still maintain the flexibility Open Source systems provide.
Developing using proprietary SDKs can be a significant sunk cost. Ultimately if another cloud provider offers a significant saving on compute, you want to be able to chase that opportunity without worrying about portability.
Thankfully, there’s also a good answer to this. Kubernetes has become the industry standard method for orchestrating technology and is heralded because of its portability. If we base ourselves in Kubernetes, one deployment script can be utilised to deploy to AWS, GCP, Azure or on premises with very little extra effort.
By approaching the vendor lock-in problem pragmatically, we combine the power of “the cloud” with the portability to take your services anywhere. This sets up your business for long term success.
3) Increased performance, visibility and customization:
Another reason to investigate your own customized solution for services such as Kafka is increased performance.
We work with clients both large and small who want to squeeze every last drop of performance out existing compute resources. By allowing flexible instance types, storage and opening up kernel parameters we have seen significant increases of throughput without costing any more. Being able to attach to and configure the runtime layer (for example JVM) also affords benefits for performance tuning.
Our experience shows that vendor provided visibility services are rather basic and lacking. By running your own Open Source solution you are free to utilize whatever monitoring solution you use, or to run our preferred Open Source system - Prometheus. With dedicated exporters you can export any relevant service metric and gain better insights into the service internals for a much lower cost.
4) Security and compliance requirements:
Strict security and compliance requirements are another reason for choosing to deploy an Open Source data lake.
Some regulations require strict data locality enforcement and/or no internet access (even in an encrypted form). Many of the systems deployed by cloud vendors do not allow for this type of deployment.
Additionally, there are cases where customer managed encryption keys or HSM keys are required. These are not always supported by a specific vendor service and may require downgrade functionality if used. By deploying an Open Source solution you are in control of encryption at rest and in transit which allows you to configure strict security policies when used.
We have deployed Open Source solutions in some of the most secure and regulated sectors on the planet. Many companies will simply not be able to use cloud vendor services which do not meet their security requirements.
5) Limited feature sets and regional availability:
Cloud managed services may not always support the features offered by the Open Source software they are based on. If we take the AWS managed Kafka service as an example, at the time of writing, the following could be considered key blockers for your workloads:
- No in-place rolling upgrades, cluster migration required to upgrade software
- Limited broker version support (1.1.1 and 2.1 only, at the time of writing)
- No custom 3rd party jars such as data balancers or metrics exporters
- No hosted schema registry
- Inter-zone network transfer costs caused by clients consuming and producing from brokers
Additionally, even within the same cloud vendor, often services are regionally available. Cloud vendors prioritize feature releases to their largest or most strategic regions. As an example, Amazon MSK is not available in the Canadian region meaning if your deployments required Canadian data locality, you will need to investigate your own solution there.
It’s important to note that it took Amazon MQ (a managed message queue) more than a year an a half to be available in the Canadian region after the initial launch of the service.
Now that we have established what might drive an organisation to adopt an Open Source data lake, we will talk about some of the design patterns and considerations to deploying them on the cloud.
We expect this series of blog posts will cover the end to end lifecycle of deploying and managing data lakes.
If you have any questions or queries, feel free to reach out to [email protected] to discuss further.




